最簡單的步驟
1. 安裝Windows server 2008
2. 去功能的地方安裝 .NET 3.5
3. 去Citrix 下載 Provisioning Service 光碟
4. 先安裝光碟內的 SQL Server
5. 點選光碟內的 autorun 開始安裝
6. 點 Server installtion
7. 點 Install Server
8. 接下來就按照他的安裝指示把server裝完,之後會自動執行configure的程式,過了基本上就裝完了
2012年11月2日 星期五
2012年10月22日 星期一
在 Windows 編輯 TeX 文件
過程做得有點長,所以我只記一下重要的部分
1. 首先去下載
http://www.tug.org/protext/
點選 download the self-extracting protext.exe file
檔案有1G多,不過請耐心下載,不然平常自己載Miktex分散載時間更久
2. 下載完之後解開,點選 setup 安裝
會出現一個視窗,分別有兩個安裝選項,先安裝MikTex,下面的是Tex編輯器,可以看你自己需求安裝它提供的,或是你在去選擇用別的Tex編輯器
3. 保險起見,按照 http://leavedcorn.pixnet.net/blog/post/24773932-%E6%96%B0%E6%89%8B%E5%AE%89%E8%A3%9Dlatex%E6%87%B6%E4%BA%BA%E6%95%99%E5%AD%B8(step-by-step) 的內容( 二的部分 )去更新了一下套件
4. 開啟TexWorks,將上面連結的範例下面的文字,複製進去TexWorks的文字編輯區
5. 在左上角綠色箭頭旁邊,將編譯器選為 xelatex ,之後按下綠色的箭頭
6. 看到有跑出 pdf 視窗就代表成功囉
7. 沒看到的話......我也還不知道可以怎麼debug,不過在編輯的時候下面會有compile的訊息,看一下下面的訊息列說不定會有什麼發現
1. 首先去下載
http://www.tug.org/protext/
點選 download the self-extracting protext.exe file
檔案有1G多,不過請耐心下載,不然平常自己載Miktex分散載時間更久
2. 下載完之後解開,點選 setup 安裝
會出現一個視窗,分別有兩個安裝選項,先安裝MikTex,下面的是Tex編輯器,可以看你自己需求安裝它提供的,或是你在去選擇用別的Tex編輯器
3. 保險起見,按照 http://leavedcorn.pixnet.net/blog/post/24773932-%E6%96%B0%E6%89%8B%E5%AE%89%E8%A3%9Dlatex%E6%87%B6%E4%BA%BA%E6%95%99%E5%AD%B8(step-by-step) 的內容( 二的部分 )去更新了一下套件
4. 開啟TexWorks,將上面連結的範例下面的文字,複製進去TexWorks的文字編輯區
5. 在左上角綠色箭頭旁邊,將編譯器選為 xelatex ,之後按下綠色的箭頭
6. 看到有跑出 pdf 視窗就代表成功囉
7. 沒看到的話......我也還不知道可以怎麼debug,不過在編輯的時候下面會有compile的訊息,看一下下面的訊息列說不定會有什麼發現
2012年10月19日 星期五
[轉載] ZFS的測試結果分析整理:(3) 我所了解的ZFS特性
- ZFS的測試結果分析整理:(3) 我所了解的ZFS特性
關於ZFS的中文資料,對於ZFS的特性,大多只是重複官方的說明,對於比較詳細的部份,著墨不多,有些甚至變成以訛傳訛的狀況。
之前做過的一些ZFS測試,有發現到一些比較特別的特性,讓我變成ZFS的教徒,所以很想詳細介紹一下,拖了很久終於生出這篇說明。
因為是個人實驗結果的整理,加上沒有親自實驗的部份來自網路上的其他文章,有錯誤的部份請提出來更正,不必客氣。
原本想再把文字內容整理的更容易了解再發表,但是因為再拖下去大概永遠不會發表了,決定先上再說。
- checksum
這是ZFS的最大特色之一,所有資料包含metadata建立時都會產生對應的checksum,可以透過checksum比較,去發現silent data corruption,並且從正確的parity資料,去修復錯誤。
但是一般宣傳時,有一個最大的誤解是(ZFS永遠不會有silent data error),正確的是ZFS一樣會發生(因為silent data error的發生是來自硬碟本身,和上層的檔案系統沒有關係),但是只要定期進行scrub檢查或任何讀出資料的動作,ZFS就能透過checksum能夠判斷資料是否是有問題。
雖然只能判斷是否有問題發生後再進行修正,但是和傳統的RAID,只能發現資料錯誤,但是無法判斷是那一個parity出錯,也無法判斷那一組parity組合是正確的相比,可以說更加可靠。
題外話,我不熟硬體RAID,但是很好奇一點,在block底層額外占一點空間加上checksum檢查好像有可能,不知道是不是已經有那一家的硬體RAID,有提供這功能。畢竟ZFS的checksum也是用cpu、記憶體和硬碟空間換來的,沒理由硬體RAID不能做到,還是說因為沒有和檔案系統結合,從block level做其實問題很大,其實是相當困難。 - COW
ZFS的COW(copy on write),對於任何要寫入的資料,無論是現有資料修改還是新增資料,一律先找空間寫入硬碟,再去修改檔案系統的配置,假如我的記憶沒有錯,ZFS連檔案配置在內的所有metadata,也同樣是依照COW的原則來寫入。所以不只是影響檔案系統下的寫入方式,讓寫入更加迅速,同時也讓RAID-Z避免了類似RAID5的write hole的發生,大幅提高對斷電等異常的安全性。
雖然有容易增加Fragment的疑慮,但是ZIL造成的Fragment似乎更為主要。 - Resilver
在pool(應該是vdev比較正確)狀態有變動時(不論是異常還是手動變更組態),ZFS會自動進行Resilver,雖然Resilver也沒有辦法用手動的方式強制執行。
最常出現的狀況就是在mirror和RAID-Z等組態中,出現故障讓硬碟暫時離線後復原或手動用replace指令更換硬碟,一定會自動啟動Resilver進行資料的同步,基本上就是一般陣列的rebuild重建,但是配合ZFS的檔案系統和陣列整合的特性,只會重建被更換的硬碟中有資料的部份,其他未使用的空間和不相同的vdev群組,ZFS並不會浪費時間去重建。甚至對於一些只是像排線接觸不良暫時離線的硬碟,在Resilver過程,也只會對離線中所修改的資料進行重建,而不必重建所有的資料。
Resilver中每次重開機的動作,都會讓Resilver的進度百分比從頭開始,那是因為ZFS是日誌型的檔案系統,Resilver只會針對日誌最後變動以來的部分進行,實際上根據ZFS日誌已經完成的部分,是不會對相同資料重複進行Resilver的。雖然出現異常自動進行Resilver時,為了資料的安全最好是讓Resilver先完成再說。 - scrub
一般情況下scrub是必須手動進行的,有點接近一般RAID陣列的rebuild重建,但是考慮到scrub檢查的是資料的checksum是否正確,只有在發現錯誤時才會有重新寫入正確資料的動作,應該是比較接近一般RAID陣列的完整性檢查。
和一般陣列相比,因為有checksum做為判斷的基準,能夠分辨出parity之中錯誤和正確的部份,並且從正確的parity中還原正確資料並加以修正。同樣的,因為和檔案系統結合,scrub只會針對有效的資料進行,不會對未使用的空間進行檢查,在效率上非常優秀。對於相同pool中的vdev也是同時進行,所以整體的完成速度,只要cpu夠力,通常只受到最慢和使用容量最大的硬碟限制。
除了定期進行scrub之外,通常在出現異常狀況,完成Resilver後,最好是再進行一次scrub好確保資料的完整性,因為以我之前的測試結果,ZFS在最極端的情況下,還是有可能發生Resilver檢查不到的錯誤(雖然那實驗已經算是惡意破壞了)。
假如在scrub進行中進行重開機,scrub進度百分比會接續在上次關機前的進度,同樣不用擔心關機會造成scrub不斷重來。 - snapshot
ZFS在進行snapshot時,我的猜測是有點接近在檔案記錄的樹狀圖上產生另外一個分支,所以建立snapshot的速度幾乎是瞬間,也不須要預留空間。
在和OpenSolaris內建的CIFS分享整合後,在windows底下snapshot會出現在以前的版本裡,和Windows使用系統保護產生的還原點相同,使用檔案總管就可以很方便的依snapshot建立時間找到舊版本的檔案,因為實在太方便,反而是ZFS自己的還原snapshot功能我不太會用。至於不用OpenSolaris內建的CIFS改用samba是否能提供相同的功能,我就不知道了。 - ZIL
為了要滿足要求同步的寫入要求,必須將資料寫入非輝發性的媒體中,再回報寫入完成。
所以ZFS準備了ZIL(ZFS intent log)負責在有同步寫入的要求出現時,就把資料先寫入ZIL後就先回報寫入完成,再找時間把的資料從記憶體內真正寫入zpool(這樣也能把一部份隨機寫入,變成效率比較高的連續寫入),最後再清除ZIL和記憶體的資料。
所以基本上zpool中一定有ZIL(ZFS intent log)的存在,ZIL一般是自動分配在zpool的vdev之中,但是在一般使用情況下ZIL只會有連續寫入(等於只是暫存,所以隨機資料一樣排隊當連續寫入),不會有從ZIL讀出資料的動作,只有在斷電或異常當機時,ZFS會透過日誌判斷那些ZIL的資料,沒有從記憶體內正確的寫入zpool,這時才會從ZIL讀取資料,完成寫入zpool的動作。
因為是分配在zpool的vdev之中,速度自然是受到zpool組態的限制,這種一般的組態下,ZIL和zpool重覆寫入,比較容易產生Fragment,對效能自然有比較大的影響,所以ZFS提供了一個先進的解決方案,可以使用獨立的ZIL,不必分配在zpool的vdev之中,不只減少Fragment,也能夠提高寫入性能。
所以網路上就出現了使用SSD當獨立ZIL後,提高整個zpool隨機寫入效能的範例,除了原本SSD小檔案隨機寫入舊優於機械式硬碟外,在ZIL會把小檔案直接連續寫入的狀況下,這種效果就會在ZFS將小檔案變成連續寫入的優點凸顯出來(不過小檔案多到,連記憶體都裝滿,zpool寫入跟不上的時候,應該還是會受到zpool本身的寫入限制吧)。
更進一步還有拿ramdisk當ZIL的測試,帳面數字很高(但是實際上和一般狀況的差異,已經超過我能理解的)範圍,不過ramdisk當ZIL這點是我倒是很想玩玩看的。
還有些測試顯示,直接關掉ZIL,ZFS的寫入效能最高,因為所有要求同步寫入的資料,都和非同步的資料一樣,暫時放在記憶體,同時也省略了ZIL的寫入動作。只是沒有ZIL,對資料的安全有很大的影響,所有的測試都強調,一般狀況下不要關掉ZIL。
部份較舊的zpool版本(v19之前),獨立ZIL故障會讓zpool無法正常import,因為在import時會檢查ZIL內的資料是否已經正確寫入zpool完成必要的資料寫入,但是故障的ZIL會讓這個動作無法完成,所以一般都是建議,資料重要的情況下,ZIL應該用mirror的組態,讓ZIL本身有備援。
只有新的zpool版本(v19以後),才能在獨立ZIL故障下,維持正常將zpool進行import,只損失獨立ZIL內未寫入的資料,但是zpool的資料還完好,使用獨立ZIL請注意這點。 - L2arc
ZFS的第一層在記憶體的快取叫arc,所以第二層就叫L2arc,L2arc是獨立的裝置,必須另外設定增加到zpool組態中,可以用比記憶體大很多的空間來快取資料。
和ZIL不同的是,因為是快取裝置,所以故障並不會造成任何資料損失,原本的資料還是完好的儲存在zpool裡面,一般多是用讀取寫入快速的SSD做L2arc。
L2arc本身需要做一段類似暖身的動作,假如觀察L2arc的讀寫動作,一般第一次寫入的資料,並不會進入L2arc,當資料第一次從zpool讀取時,這時候才會看到重覆讀取的資料,同時寫入L2arc,這之後再讀取相同資料,才會有從L2arc讀取資料的加速效果。
比較特別的是,假如讀取的資料不大,或是是ZFS系統的記憶體又夠大,ARC可以放的下讀取的資料,就只會觀察到寫入L2arc的動作,但是重覆讀取還是由記憶體中的ARC負責,因為記憶體的ARC空間還是足夠。 - zpool
zpool => vdev => HDD - vdev
zpool在組成和存取資料時的基本單位,vdev可以視為一個在zpool內虛擬的硬碟(裝置),所有的zpool都是由vdev所組成,vdev本身再由單一硬碟、mirror和RAID-Z等不同組態形成。
ZFS在將資料寫入zpool時,會自動將資料分配在zpool內的各vdev,接近RAID0但是並非100%等分,而是動態分配至各vdev,ZFS會依各vdev的狀態(online、degrade),決定寫入資料的分配方式。
讀取時因為動態分配寫入的特性,會同時從哪幾個vdev讀取,全看寫入資料時的分布狀態,所以理想狀態會接近RAID0的讀取,最差的狀況就是從單一vdev讀取的速度。
vdev的數量,影響iops的高低,所以zpool組成中總硬碟數量相同時,分成較多組小的vdev,通常會損失較多有效容量(vdev是有備援的RAID-Z和mirror情況下),但是可以提高iops。 - vdev組態RAID-Z
從RAID-Z1、RAID-Z2到RAID-Z3的備援組態,分別允許vdev組成之中有1到3個的硬碟損壞,還能保持資料的完整,而效能的部份,每一組RAID-Z組成的vdev讀寫頻寬大約是RAID-Z1(n-1)、RAID-Z2(n-2)、RAID-Z3(n-3),每一組vdev的iops約等於單一硬碟,所以保護和效能大約就是和一般的RAID5和RAID6相似。
但是因為ZFS的COW和動態分割大小等特性,並不會有write hole 的問題發生,因為在寫入資料時,不需要因為儲存資料的block共用問題,去讀取資料再把更新後的資料寫入,所以不會發生要寫入資料A,結果因為意外寫入資料未完成,所以連原本完整的資料B(和資料A共用block)都一起出問題。
同時也因為寫入前不必有讀取的動作,自然在效能上占有優勢。 - vdev組態mirror
mirror基本上就是RAID1,但ZFS的mirror可以用2個以上的硬碟,為了安全可以用上3個甚至4個硬碟mirror(數量上限要查)。
配合ZFS的checksum功能,讀取資料時可以從vdev中的硬碟,分別讀取不同區塊的資料,進行checksum檢查ok後再合併資料輸出,所以讀取效能接近RAID0。
寫入效能因為是mirror,所以vdev中的每一個硬碟都要寫入相同資料,所以寫入效能接近RAID1。
另外,在較新的zpool版本,mirror可以使用split指令分開為獨立的兩個zpool - zpool擴充方式
想要擴充zpool的容量,最基本的方式就是增加新的vdev到zpool之中,新的vdev可以是單顆硬碟、mirror及RAID-Z任一種組態。加入新的vdev之後增加的空間,立刻就會反應到檔案系統上,存在舊有vdev上的資料,則會保持在原本的位置。
不過,已經加入zpool的vdev沒有辦法單獨移除,需要破壞zpool再進行重建,才能改變zpool的組態。(在zpool v28以上,ZIL和cache這兩種vdev,可以直接在線上進行加入和移除,算是例外。) - vdev的擴充
再進一步討論到vdev的擴充,最基本的原則就是vdev本身的組成(單一硬碟、mirror或RAID-Z),在建立之後就沒辦法變更。想要擴充vdev的容量,就只能用replace指令一次一個將組成的硬碟換成容量較大的,並且等待Resilver完成再換下一個硬碟,直到vdev中所有硬碟都替換並Resilver完成,最後再將zpool export後再重新import,這樣就可以完成vdev的擴充,增加的容量就可以被ZFS使用。 - zpool在異常狀況下的讀取行為,要由下往上由HDD、vdev到zpool的層級來看
對於最底層的HDD,除了完全無法讀取的狀況外,ZFS基本上是能讀取多少就讀取多少,再由checksum決定資料是否可以使用,所以和一般硬體RAID會利用類似TLEA指令讓問題HDD提早離線,盡早讓Hot Spare的HDD替換上來的原則不同,所以ZFS希望直接控制底層的HDD,而不要在硬體RAID之上使用ZFS,太早就把問題HDD離線,正是理由之一,畢竟兩種處理原則是有衝突的。ZFS針對checksum異常太多的HDD,才會把HDD設為offline(我不是很確定條件),無法再進行存取。
從vdev的層級來看,單一HDD組成的vdev因為沒有任何備援,所以異常狀態下vdev的讀取行為大致上和單一HDD相同。(這部分到是沒有測試過,也想不到要用沒有備援的vdev和zpool的理由)
異常狀況下,mirror和RAID-Z組成的vdev很相似,假如組成vdev的HDD只是有讀取異常(chechsum錯誤或部分無法讀取的資料),基本上就從其他正常的HDD取得checksum正確的資料。同時會利用其他HDD正確的資料,重新寫入讀取錯誤的HDD,回復資料的備援狀態。
假如是有HDD因為異常過多,被ZFS判定為fail而offline(或是被拔線),mirror的讀取效能就會受到影響,因為原本分散讀取的來源變少了,RAID-Z部分因為原本就要從vdev中所有的HDD讀取資料,我之前的測試顯示連續讀取的效能並沒有明顯的影響,可能因為ZFS並不會浪費時間在offline和fail的HDD上。
從zpool的層級來看,因為zpool中的vdev大約等於RAID0中的HDD,只是資料並不是完全平均分布在所有的vdev之中,所以一但vdev因為底下的HDD異常讓vdev進入fail或offline狀態,就看動態分配的資料有沒有在fail的vdev之中,來決定資料能不能讀出來,所以有機會只有有部分資料被影響。但是大部分的情況下,因為通常資料都還是接近平均分配,所以vdev故障和RAID0相同,代表著zpool的資料無法讀取。 - zpool在異常狀況下的寫入行為,要反過來由上往上下zpool、vdev到HDD的層級來看
對於最上層的zpool,由底下組成的vdev狀態決定,只要有任何vdev是fail,整個zpool就是fail狀態,系統是完全無法寫入資料,當然開機時也就無法mount。
假如有其中之一的vdev進入degrade狀態,整個zpool就會進入degrade狀態,在只有單一vdev組成的zpool中,會繼續寫入僅有的vdev之中,因為ZFS也沒有其他的選擇,但是因為ZFS動態分配寫入資料的特性,對於多個vdev所組成的zpool,只要正常的vdev空間足夠,ZFS在動態分配寫入資料時,就會避開已經是degrade狀態的vdev,只把資料寫入有正常備援保護的vdev中,確保資料備援的完整性。
在我之前測試結顯示,就算所有的vdev目前的狀態是正常的,也似乎會因為vdev曾經進入fail或是degrade狀態,而讓動態分配寫入的優先順序改變,只是之前的測試時在是判斷不出判斷優先順序的規則。
最後針對最底層的HDD,基本上最單純,就是盡可能的寫入資料,直到錯誤太多被判定成fail(mirror和RAID-Z等有備援上層vdev進入degrade狀態,沒有備援的vdev就直接進入fail)或degrade(上層vdev進入degrade)。 同樣的,對於架構在硬體RAID之上的ZFS系統,因為無從控制硬體RAID對異常的處理方式,上列的安全機制是完全沒有作用的,這是同樣是另一個盡量讓ZFS直接存取底層HDD的理由。 - 正常和異常狀態下,使用replace指令更換HDD
除了和一般RAID相同,拔舊的換新的HDD這種1對1交換外,只要還有足夠的port和電源,新舊HDD可以同時接上,也可以同時有兩組以上HDD進行交換。從我之前的實驗中,可以發現下列幾個優點。
對於正常的zpool,在舊HDD存在的情況下,不會進入degrade狀態,可以保持完整的備援,同時進行新HDD的Resilver動作。更進一步,因為可以同時從舊HDD讀取資料,只要還沒達到新HDD的寫入限制前,還有機會提高Resilver的速度。
對於degrade的zpool,只要舊HDD沒有進入完全無法讀取的fail狀態,除了舊HDD終無法讀取的資料失去備援外,其他還能讀取的資料還是能保持完整的備援,不會因為1對1交換而進入沒有備援狀態。同樣的Resilver時,也會盡可能讀取還能正常讀取的部分,來加速Resilver的完成。
所以使用ZFS需要更換HDD時,只要還有足夠的port和電源,請盡可能同時接上新舊HDD,不只提高安全性,還有機會縮短完成交換的時間。
2012年10月17日 星期三
[轉載] Open vSwitch 架構概觀
原文網址: http://mlwmlw.org/2012/04/open-vswitch-component-overview/


看了 open vswitch 也有一陣子了,斷斷續續也在自己的 wiki 上亂寫了一些東西,但是一直覺得自己不夠熟,也不知道從哪裡開始整理,先在這寫一些概念性的解釋…
官方資料內有一個關於 porting 的文件,裡面畫了實作上的一些抽象元件,幫助你決定要移植 ovs 時,要改寫哪個部份,如下圖。一開始看這張圖應該會有點霧煞煞,對 ovs 的很多概念還不熟悉,不知道從哪裡開始瞭解,看完文件的解釋還是不太懂。
| +-------------------+
| | ovs-vswitchd |<-->ovsdb-server
| +-------------------+
| | ofproto |<-->OpenFlow controllers
| +--------+-+--------+ _
| | netdev | |ofproto-| |
userspace | +--------+ | dpif | |
| | netdev | +--------+ |
| |provider| | dpif | |
| +---||---+ +--------+ |
| || | dpif | | implementation of
| || |provider| | ofproto provider
|_ || +---||---+ |
|| || |
_ +---||-----+---||---+ |
| | |datapath| |
kernel | | +--------+ _|
| | |
|_ +--------||---------+
||
physical
NIC
我自己則是從他安裝完所提供的各種工具與重要背景服務的角度開始,由此開始熟悉 ovs 的概念,感覺這是一個比較好的入門點。我畫了一張類似的圖。
+---------+ +----------+ +---------+ +---------+
|ovs-ofctl| |ovs-appctl| |ovs-vsctl| |ovs-dpctl|
+---------+ +----------+ +---------+ +---------+
^ ^ USER SPACE TOOLS ^ ^
+-------|-------|------------------|-- --------|----+
v v v |
+--------------+ +----------------+ |
| | | | |
| ovs-vswitchd | <---> | ovsdb-server | |
| | | | |
+--------------+ +----------------+ |
^ USER SPACE DAEMONS |
+----------|-----------------------------------|----+
v KERNEL SPACE v
+------------------------------------------+
| |
| datapath |
| |
+------------------------------------------+
datapath – openvswitch_mod.so 當 ovs 以 kernel 模組運作時在核心中的單元,主要處理在核心交換封包到各介面的工作。datapath 應該也能當作 vswitch 在 kernel 中的 instance,可以有好幾個 datapath 。
USER SPACE DAEMONS - 開啟 ovs 需要啟動的兩個背景程式
- ovsdb-server:用來儲存所有 ovs 設定資料的簡易資料庫,設定完會看情況通知 datapath(kernel)同步狀態,統計資料也會存在這 。所有能設定的欄位跟解釋都在這份文件 內。
- ovs-vswitchd:用來跟 openflow 控制器溝通與 ovsdb 溝通。可以讓你設定你的 vswitch 要跑在什麼模式。
USER SPACE TOOLS:
- ovs-vsctl : 對 ovsdb 操作,操作指令比較具有語意,會幫你轉化成 ovsdb 看的懂的語法,例如建立 bridge、指定 bridge port 的對應、設定 Bridge Port Interface etc
- ovs-dpctl : 管理 datapath 的工具,大部分資訊都是透過 netlink 反應出 datapath 目前的狀態,也可以直接操作 datapath 中目前的 flow。
- ovs-ofctl : openflow switch 管理工具,可以操作與 openflow 相關的設定,是設定 ovs-vswitchd 的不是 datapath 的。在這裡設定一些靜態的 flow 之後會被轉化更實體的 flow 同步到 datapath 中。例如預設的 flow 是 rule=*,action=normal,就是把 ovs-vswitchd 當成一個 learning switch。設了 controller 以後就是讓 flow 再間接去問控制器,再從控制器產生 flow 存放到 ovs-vswitchd 內,ovs-dpctl 跟 ovs-ofctl 都可以用 dump-flows 印 flows 出來看 。
- ovs-appctl : ovs-vswithd 的管理工具,可以跟 ovs-vswitchd 程序溝通,所以要指定的是 ovs-vswitchd 的 pid。例如可以用來印出 forwarding table。
找到畫這圖的有趣的軟體:http://www.asciiflow.com/
[轉載] 雲中的網絡:Open vSwitch帶來的巨變
計算,存儲,網絡,安全,是構建任何大型數據中心都繞不過去的四個問題。雲也不例外。在這個風起雲湧的雲時代,各廠商賽馬般發佈層出不窮的新技術,著實讓我們目不暇接。很多人昨天剛玩過Xen,今天看到Redhat宣稱KVM是其新的戰略方向,又忍不住把KVM拿來折騰一番。大家習慣性地把注意力都放在了「計算」上,積累了不少「服務器虛擬化」的經驗,卻不知不覺冷落了其餘三個方面。國外同行們熱議Software Defined Network(SDN)和OpenFlow這些因為雲而瞬間火爆的技術時,我們還卯足了勁兒一頭紮進服務器虛擬化中不願出來。
搜索了一下,網絡上關於「網絡虛擬化」的文章很少。工作關係長期接觸這方面技術,不敢私藏,拿出來跟大家分享一下。水平有限,純屬拋磚引玉,大家扔磚頭時輕一點。歡迎討論,歡迎站短,歡迎郵件 cloudbengo@gmail.com
什麼是Open vSwitch?它能給雲帶來什麼?
Open vSwitch的目標,是做一個具有產品級質量的多層虛擬交換機。通過可編程擴展,可以實現大規模網絡的自動化(配置、管理、維護)。它支持現有標準管理接口和協議(比如netFlow,sFlow,SPAN,RSPAN,CLI,LACP,802.1ag等,熟悉物理網絡維護的管理員可以毫不費力地通過Open vSwitch轉向虛擬網絡管理)。
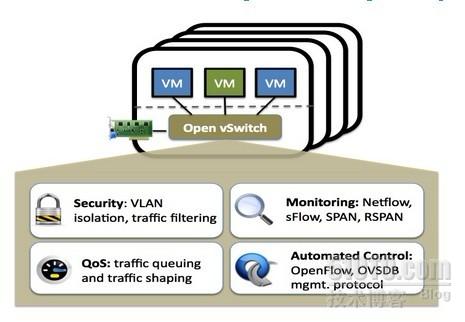
圖一:Open vSwitch示意圖
官網的描述精準而抽象,來點通俗的,Open vSwitch是一個由Nicira Networks主導的開源項目,通過運行在虛擬化平台上的虛擬交換機,為本台物理機上的VM提供二層網絡接入, 跟雲中的其它物理交換機一樣工作在Layer 2層。Open vSwitch充分考慮了在不同虛擬化平台間的移植性,採用平台無關的C語言開發。最為人民群眾喜聞樂見的是,它遵循Apache2.0許可,不論你是自用還是商用都OK。而它的同類產品VMware的vDS(vSphere Distributed VirtualSwitch),Cisco的Nexus 1000V都是收費的。更重要的是,雖然免費,其產品質量卻深得信賴。在2010年Open vSwitch 1.0.0發佈之前,Citrix就宣佈在XenServer中將其作為默認組件。關於這一點,也許Nicira的身世可以給出一些解釋,它的投資人裡有Diane Greene(VMware聯合創始人)和Andy Rachleff(Benchmark Capital聯合創始人),經常聽朋友談起的幾個VMware網絡大牛也加盟其中,是目前硅谷最炙手可熱的SDN創業公司之一。
既然Citrix的企業級虛擬化產品都裝備了Open vSwitch,我們還有什麼理由懷疑它的可靠性呢?更何況它還是開源的!
你可能會問,我為什麼有必要在自己的雲架構中使用它呢?它能給我的雲帶來什麼?
OK。需求決定一切,如果你只是自己搞一台Host,在上面虛擬幾台VM做實驗。或者小型創業公司,通過在五台十台機器上的虛擬化,創建一些VM給公司內部開發測試團隊使用。那麼對你而言,網絡虛擬化的迫切性並不強烈。也許你更多考慮的,是VM的可靠接入:和物理機一樣有效獲取網絡連接,能夠RDP訪問。Linux Kernel自帶的橋接模塊就可以很好的解決這一問題。原理上講,正確配置橋接,並把VM的virtual nic連接在橋接器上就OK啦。很多虛擬化平台的早期解決方案也是如此,自動配置並以向用戶透明的方式提供虛擬機接入。如果你是OpenStack的fans,那Nova就更好地幫你完成了一系列網絡接入設置。Open vSwitch在WHY-OVS這篇文章中,第一句話就高度讚揚了Linux bridge:
「We love the existing network stack in Linux. It is robust, flexible, and feature rich. Linux already contains an in-kernel L2 switch (the Linux bridge) which can be used by VMs for inter-VM communication. So, it is reasonable to ask why there is a need for a new network switch.」
但是,如果你是大型數據中心的網絡管理員,一朵沒有網絡虛擬化支持的雲,將是無盡的噩夢。
在傳統數據中心中,網絡管理員習慣了每台物理機的網絡接入均可見並且可配置。通過在交換機某端口的策略配置,可以很好控制指定物理機的網絡接入,訪問策略,網絡隔離,流量監控,數據包分析,Qos配置,流量優化等。
有了雲,網絡管理員仍然期望能以per OS/per port的方式管理。如果沒有網絡虛擬化技術的支持,管理員只能看到被橋接的物理網卡,其上川流不息地跑著n台VM的數據包。僅憑物理交換機支持,管理員無法區分這些包屬於哪個OS哪個用戶,只能望雲興嘆乎?簡單列舉常見的幾種需求,Open vSwitch現有版本很好地解決了這些需求。
需求一:網絡隔離。物理網絡管理員早已習慣了把不同的用戶組放在不同的VLAN中,例如研發部門、銷售部門、財務部門,做到二層網絡隔離。Open vSwitch通過在host上虛擬出一個軟件交換機,等於在物理交換機上級聯了一台新的交換機,所有VM通過級聯交換機接入,讓管理員能夠像配置物理交換機一樣把同一台host上的眾多VM分配到不同VLAN中去;
需求二:QoS配置。在共享同一個物理網卡的眾多VM中,我們期望給每台VM配置不同的速度和帶寬,以保證核心業務VM的網絡性能。通過在Open vSwitch端口上,給各個VM配置QoS,可以實現物理交換機的traffic queuing和traffic shaping功能。
需求三:流量監控,Netflow,sFlow。物理交換機通過xxFlow技術對數據包採樣,記錄關鍵域,發往Analyzer處理。進而實現包括網絡監控、應用軟件監控、用戶監控、網絡規劃、安全分析、會計和結算、以及網絡流量數據庫分析和挖掘在內的各項操作。例如,NetFlow流量統計可以採集的數據非常豐富,包括:數據流時戳、源IP地址和目的IP地址、 源端口號和目的端口號、輸入接口號和輸出接口號、下一跳IP地址、信息流中的總字節數、信息流中的數據包數量、信息流中的第一個和最後一個數據包時戳、源AS和目的AS,及前置掩碼序號等。
xxFlow因其方便、快捷、動態、高效的特點,為越來越多的網管人員所接受,成為互聯網安全管理的重要手段,特別是在較大網絡的管理中,更能體現出其獨特優勢。
沒錯,有了Open vSwitch,作為網管的你,可以把xxFlow的強大淋漓盡致地應用在VM上!
需求四:數據包分析,Packet Mirror。物理交換機的一大賣點,當對某一端口的數據包感興趣時(for trouble shooting , etc),可以配置各種span(SPAN, RSPAN, ERSPAN),把該端口的數據包複製轉發到指定端口,通過抓包工具進行分析。Open vSwitch官網列出了對SPAN, RSPAN, and GRE-tunneled mirrors的支持。
關於具體功能,就不一一贅述了,感興趣的童鞋可以參考官網功能列表:http://openvswitch.org/features/
只是在Open vSwitch上實現物理交換機的現有功能?那絕對不是Nicira的風格。
雲中的網絡,絕不僅僅需要傳統物理交換機已有的功能。雲對網絡的需求,推動了Software Defined Network越來越火。而在各種SDN解決方案中,OpenFlow無疑是最引人矚目的。Flow Table + Controller的架構,為新服務新協議提供了絕佳的開放性平台。Nicira把對Openflow的支持引入了Open vSwitch。引入以下模塊:
‧ ovs-openflowd --- OpenFlow交換機;
‧ ovs-controller --- OpenFlow控制器;
‧ ovs-ofctl --- Open Flow 的命令行配置接口;
‧ ovs-pki --- 創建和管理公鑰框架;
‧ tcpdump的補丁 --- 解析OpenFlow的消息;
不再展開,大家感興趣的話可以Google之。
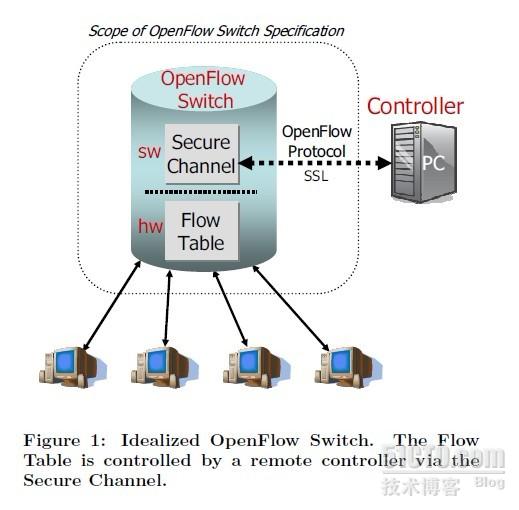
圖2 :Open Flow示意圖 -- 摘自Open Flow白皮書
需求決定產品,正是由於在企業級雲中,需要各種豐富的網絡功能,VMware才於n年前就推出了vSwitch、vDS等虛擬交換機。正是看到了雲中的網絡是一塊大市場,Cisco才與VMware緊密合作,以partner的形式基於VMware kernel API開發出了自己的分佈式虛擬交換機Nexus 1000V(功能對應於VMware的vDS)。可惜的是,這兩款產品都是收費的。Citrix倒是基於Open vSwitch快速追趕,推出了自己的Distributed Virtual Switch解決方案。但是不好意思,也是收費的。開源雲的標竿OpenStack去年下半年推出了一項宏大的計劃,啟動了Quantum項目,志在通過引入Open vSwitch,為Open Stack Network模塊勾勒出「Connectivity as a service」的動人前景。有時間的話,會再單獨開一篇文章討論。
感謝開源,Open vSwitch是坐公交車的成本,進口跑車的體驗!還等什麼,在你的大型開源雲架構中,使用Open vSwitch吧!
(目前網上關於雲環境中網絡虛擬化的中文文章比較少,拋磚引玉一下,歡迎大家拍磚,歡迎留言提問或質疑,關於OVS,SDN,OpenFlow都行,大家在討論中一起進步)
2012年10月16日 星期二
[轉載] 多核心計算環境—NUMA與CPUSET簡介
原文網址: http://www.cc.ntu.edu.tw/chinese/epaper/0015/20101220_1508.htm
多核心計算環境—NUMA與CPUSET簡介
作者:周秉誼 / 臺灣大學計算機及資訊網路中心作業管理組碩士後研究人員
多核心處理器的普及化,使得計算環境和軟體及系統設計有了很大的變化。NUMA架構帶來異質的記憶體存取環境,也變成系統管理和使用計憶體的一個挑戰。在了解硬體的NUMA架構後,配合CPUSET功能,適當地分配應用程式或高效能計算工作到特定的處理器上,是一個簡便卻能夠減少記憶體存取時間、提高計算效能的方式。
前言中央處理器 (Central Processing Unit, CPU) 是執行計算程式指令的元件,也是影響計算效能最重要的部份。從1970年代開始,中央處理器的進步速度就像著名的摩爾定理 (Moore’s Law) 所描述,每十八個月處理器中的電晶體數量就會成長一倍,處理器的效能也隨著電晶體數量增加,而能夠用更快的速度進行計算工作。但是,當電晶體的數量成長到一定的規模,處理器龐大的架構和設計的複雜程度也成為增進處理器效率和研發新架構的包袱。為了讓小小的處理器能夠做更多的事情,就產生了另一種想法:為何不在同一個處理器裡放入更多的核心呢,因而出現了多核心處理器 (multi-core processor)。
多核心處理器多核心處理器是指,在同一個處理器的晶片封裝 (chip package) 中放入多個處理器核心 (core),而這些核心在作業系統中都可以被視為是獨立的處理器單元,讓多個程式或執行緒 (thread) 可以同時在不同的核心中進行計算工作。在處理器的架構上,這些核心就是實際在執行計算指令 (instruction) 的部份,在常見的架構中同一個封裝的核心會共享底層的資源,如快取記憶體 (cache),並使用同一個匯流排 (bus) 來與處理器外部溝通。不同架構的多核心處理器也已經被廣泛地使用在各種計算需求的領域,如GPU、DSP、網路路由器、手機及電視遊戲主機等。
Intel及AMD等主流個人電腦中央處理器供應商,在時脈提升和能源散熱的問題碰到瓶頸後,也開始推出個人電腦市場的多核心中央處理器。目前市場上最新的Core i7在單一封裝中可以達到6個核心,而更多核心的處理器也在設計當中,在單一電腦中擁有數十個計算核心,也將不是昂貴的大型主機才有的特徵。
這樣的進步也造福了高效能運算的使用者,多核心處理器使同樣的機房、機櫃空間中,可以放入更多的計算核心,也可以提供更多的計算能力。以往八個核心的平行計算,要使用兩三台電腦才能進行,還需要呼叫MPI (Message Passing Interface) 的函式庫、透過高速網路才能在不同電腦間同步及資料交換;現在只需要一台具有兩個四核心處理器的電腦就可以完成了,還可以利用共享記憶體 (shared memory) 來進行資料交換,延遲時間 (latency) 比使用gigabit乙太網路快上不少。
NUMA架構然而,就算在同一台電腦中,尤其是有多個處理器的系統,不同核心之間訊息傳遞的速率會有些不同,不同核心存取不同區段記憶體的速率也可能會不一樣。這是因為當系統中的核心數量較多時,原本的對稱式多處理器 (Symmetric Multi-Processor, SMP) 設計,在處理器和記憶體間的匯流排將會成為資料存取的瓶頸,會嚴重地影響到系統效能。NUMA (Non-Uniform Memory Access) 的設計簡化了匯流排的複雜程度,NUMA把系統切成數個節點 (node),每個處理器及記憶體就位在某一個節點上,當處理器存取同一個節點的記憶體時,可以有較高的存取速度;而存取其他節點的記憶體時,就需要透過節點間的資料傳遞,會耗費較多時間。

作業系統中為了提高記憶體存取的效率,會針對硬體的NUMA配置來設定記憶體存取的策略 (policy),並提供NUMA相關的程式介面 (API) 來查詢系統NUMA配置和修改存取策略。以GNU Linux為例,作業系統的核心 (kernel) 在2.6版後,就會依據硬體架構的NUMA設計,進行記憶體的配置,並提供NUMA相關的系統呼叫函式 (system call) 供程式使用;在 /proc這個程序虛擬檔案系統 (proc file system) 裡,也有numa_maps檔案可以查詢某個程序 (process) 的記憶體配置。另外也有numactl指令,可以查詢系統的NUMA狀況及改變記憶體配置的策略。

因為NUMA架構的影響,當利用共享記憶體進行需要資料交換的平行計算時,如果進行計算的執行緒在不同節點的核心的話,共享記憶體存取的效率就會下降,所以需要了解每個執行緒是被那一個核心所執行。在Linux的環境中,要觀察目前正在執行的程式狀態可以使用top指令,配合-H參數可以顯示所有的執行緒,進入top指令的介面後,打開Last used CPU的資訊,就可以了解每一個執行緒是被那一個核心執行的。參考numactl指令得到的NUMA架構資訊,可以知道每一個核心所屬的節點和每個節點的記憶體配置,利用這些資訊就能規劃執行緒與核心的分配。

CPUSET功能在Linux中要控制每一個程序在那個核心執行,可以使用CPUSET的功能。CPUSET是Linux核心2.6版中的一個小模組,它可以讓使用者將多核心的系統切割成不同區域,每個區域包括了處理器和實體記憶體的區段。使用者可以指定某個程式只能在特定的區域執行,而且該程式不能使用該區域之外的計算資源。一般的應用,如網頁伺服器 (web server)、有多種不同性質程式一同運作的伺服器,或有NUMA架構的高效能運算伺服器,都可以使用CPUSET的功能來增進效率。想確認自己的Linux核心是否有開啟CPUSET功能,可以在/boot下的Linux核心config檔案裡,尋找CONFIG_CPUSET的旗標 (flag) 有沒有開啟。
要使用CPUSET來建立區域和調整程序執行位置的其中一個方式,是使用CPUSET虛擬檔案系統 (CPUSET pseudo filesystem)。首先以mount指令將CPUSET檔案系統掛載在/dev/cpuset下,/dev/cpuset這個目錄就代表了整個系統可用的資源,是最基本的一個CPUSET區域。在/dev/cpuset目錄裡可以找到一些檔案,其中cpus檔的內容是在這個CPUSET下可用的處理器編號;mems檔的內容是這個CPUSET下可用的實體記憶體區段;tasks檔的內容是可在這個CPUSET下執行的程序編號 (Process ID, PID)。如果要建立一個新的CPUSET,就在/dev/cpuset下使用mkdir指令建立一個目錄,目錄建立後會自動產生cpus、mems、tasks等檔案。要修改這個CPUSET可用的處理器就用echo指令將處理器編號寫入cpus檔案,要新增程序到這個CPUSET就用echo指令將程序編號寫入tasks檔案。也可以在一個CPUSET下建立多個子集合,進行比較複雜的資源設定。要移除一個CPUSET就用rmdir指令直接移除該CPUSET的目錄就可以了,但是如果該CPUSET中還有程序在進行或還有子集合存在,就沒有辦法移除。

CPUSET使用實例工作排程系統 (job scheduler, batch system, queuing system) 在高效能運算的叢集系統 (cluster) 上,一直扮演很重要的角色,讓計算資源可以公平公正地分享給所有計算工作。而在工作排程系統上使用CPUSET功能,可以讓工作排程系統在多核心的計算環境中,做到更精確地計算資源控制。TORQUE是一套開放原始碼 (open source) 的工作排程系統,它是從PBS (Portable Batch System) 及OpenPBS延伸出來的,廣泛地使用在各種高效能計算領域的資源管理。TORQUE從2.3版之後開始支援Linux 2.6核心的CPUSET,只要在編譯時打開CPUSET功能,就會在後端計算節點開啟CPUSET並自動配置計算資源。當計算節點的TORQUE服務啟動時,就會先在/dev/cpuset建立一個TORQUE的CPUSET;當有計算工作開始進行,TORQUE服務會依據該工作提出的處理器數量需求,建立一個CPUSET子集合,再把該工作的程序都分配到這個CPUSET中。因為被限制在某一個CPUSET中執行,這樣就能防止單一工作佔用其他工作的計算資源。
結語隨著處理器的核心數量一直增加,NUMA架構的計算環境也會更為常見。配合CPUSET能夠有效地控制執行每個應用程式或系統服務的處理器,將會增進系統和計算工作的效能;反之,如果忽略了NUMA架構的特性,會對系統效能有很大的衝擊。例如,VMWare等提供虛擬化 (virtualization) 系統環境的產品,都有針對NUMA架構最佳化的設計和演算法。在個人使用的環境下,想要調效多核心環境的計算效能,Linux核心提供的CPUSET功能會是一個簡單而方便的操作方式。
2012年10月11日 星期四
[memo] get http url from tcpdump
just record it
article from: http://fixunix.com/networking/11042-tcpdump-show-requested-web-addresses.html
article from: http://fixunix.com/networking/11042-tcpdump-show-requested-web-addresses.html
Re: tcpdump show requested web addresses
> IMHO, Squid running as a transparent proxy and Sarg for Squid can be a
> better solution for this kind of problem domain, besides this you
too heavyweight, I only want to sometimes see accessed sites at the
moment
> man tcpdump
> man awk
I had checked, this is the farthest I can go:
# tcpdump -A -i eth0 -vvv -s 500 'tcp port 80 and ip[2:2] > 40 and
tcp[tcpflags] & tcp-push != 0 and dst port 80' -f
18:56:32.608664 IP (tos 0x0, ttl 128, id 65255, offset 0, flags [DF],
proto: TCP (6), length: 1087) 192.168.0.2.leoip > 64.233.179.99.http:
P 2815965847:2815966894(1047) ack 2615566913 win 65535
E..?..@...B.....@..c.^.P..:...bAP...q...GET /groups/favorites HTTP/1.1
Accept: */*
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60;
__utma=118165087.413883557.1169431526.1173112823.1 173117250.94;
__utmz=118165087.1171542698.32.2.utmccn=(organic)| utmcsr=google|
utmctr=download+jpeg+dotn
18:56:35.157940 IP (tos 0x0, ttl 128, id 65402, offset 0, flags [DF],
proto: TCP (6), length: 1240) 192.168.0.2.leoip > 64.233.179.99.http:
P 1047:2247(1200) ack 13482 win 65535
E....z@...A.....@..c.^.P..>.....P...MS..GET /groups/static/release/
g2_common-2808fcbcb36accc4345bd5927f3708e2.js HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Fri, 16 Feb 2007 22:27:45 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60;
18:56:35.785548 IP (tos 0x0, ttl 128, id 65435, offset 0, flags [DF],
proto: TCP (6), length: 1196) 192.168.0.2.leoip > 64.233.179.99.http:
P 2247:3403(1156) ack 13630 win 65387
E.....@...A.....@..c.^.P..C^...~P..ks...GET /groups/img/envelope.gif
HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:50 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.117311
18:56:36.477664 IP (tos 0x0, ttl 128, id 65477, offset 0, flags [DF],
proto: TCP (6), length: 1205) 192.168.0.2.leoip > 64.233.179.99.http:
P 3403:4568(1165) ack 13778 win 65239
E.....@...A.....@..c.^.P..G.....P.......GET /groups/img/3nb/
groups_medium.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:48 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.11694315
18:56:36.609755 IP (tos 0x0, ttl 128, id 65492, offset 0, flags [DF],
proto: TCP (6), length: 1199) 192.168.0.2.ncconfig >
64.233.179.99.http: P 2844376055:2844377214(1159) ack 2477796145 win
65535
E.....@...A}....@..c.`.P......+1P.......GET /groups/img/
mygroups_lt.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:38:02 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.117
18:56:37.092568 IP (tos 0x0, ttl 128, id 65521, offset 0, flags [DF],
proto: TCP (6), length: 1186) 192.168.0.2.leoip > 64.233.179.99.http:
P 4568:5714(1146) ack 13926 win 65091
E.....@...Am....@..c.^.P..Lo....P..C....GET /images/x2.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Fri, 21 Jul 2006 18:17:14 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60;
__utma=118165087.413883557.1169431526.1173112823.1 1731
18:56:37.130598 IP (tos 0x0, ttl 128, id 65526, offset 0, flags [DF],
proto: TCP (6), length: 802) 192.168.0.2.wilkenlistener >
66.102.9.104.http: P 367:1129(762) ack 164 win 65372
E.."..@....f....Bf h.b.PU.~m....P..\.M..GET /__utm.gif?
utmwv=1&utmn=37005535&utmcs=utf-8&utmsr=1280x1024&utmsc=32-
bit&utmul=en-us&utmje=1&utmfl=9.0&utmdt=Google
%20Groups&utmhn=groups.google.com&utmr=-&utmp=/groups/
favorites&utmac=UA-1044941-1&utmcc=__utma
%3D118165087.413883557.1169431526.1173112823.11731 17250.94%3B%2B__utmb
%3D118165087%3B%2B__utmc%3D118165087%3B%2B__utmz
%3D118165087.1171542698.32.2.utmccn%3D(organic)%7C utmcsr%3Dgoogle
%7Cutmctr%3Ddownload%2Bjpeg%2Bdotnet%7Cutmcmd%3D
18:56:37.466336 IP (tos 0x0, ttl 128, id 4, offset 0, flags [DF],
proto: TCP (6), length: 1197) 192.168.0.2.ncconfig >
64.233.179.99.http: P 1159:2316(1157) ack 149 win 65387
E.....@...AP....@..c.`.P...~..+.P..k.
...GET /groups/img/watched_y.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:38:04 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.11731
18:56:37.597895 IP (tos 0x0, ttl 128, id 11, offset 0, flags [DF],
proto: TCP (6), length: 1199) 192.168.0.2.leoip > 64.233.179.99.http:
P 5714:6873(1159) ack 14068 win 64949
E.....@...AG....@..c.^.P..P....4P.......GET /groups/img/
threadsub_y.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:38:03 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.117
18:56:38.161750 IP (tos 0x0, ttl 128, id 43, offset 0, flags [DF],
proto: TCP (6), length: 1198) 192.168.0.2.ncconfig >
64.233.179.99.http: P 2316:3474(1158) ack 297 win 65239
E....+@...A(....@..c.`.P......,YP.......GET /groups/img/fusion_add.gif
HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:50 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.1173
18:56:38.177656 IP (tos 0x0, ttl 128, id 52, offset 0, flags [DF],
proto: TCP (6), length: 1200) 192.168.0.2.leoip > 64.233.179.99.http:
P 6873:8033(1160) ack 14216 win 64801
E....4@...A.....@..c.^.P..Up....P..!....GET /groups/img/
corner_tleft.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:49 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.11
18:56:38.762751 IP (tos 0x0, ttl 128, id 64, offset 0, flags [DF],
proto: TCP (6), length: 1201) 192.168.0.2.ncconfig >
64.233.179.99.http: P 3474:4635(1161) ack 445 win 65091
E....@@...A.....@..c.`.P......,.P..CA...GET /groups/img/
corner_tright.gif HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:49 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.1
18:56:39.046125 IP (tos 0x0, ttl 128, id 81, offset 0, flags [DF],
proto: TCP (6), length: 1197) 192.168.0.2.leoip > 64.233.179.99.http:
P 8033:9190(1157) ack 14364 win 64653
E....Q@...A.....@..c.^.P..Y....\P....=..GET /groups/img/dot_clear.gif
HTTP/1.1
Accept: */*
Referer: http://groups.google.com/groups/favorites
Accept-Language: pl
UA-CPU: x86
Accept-Encoding: gzip, deflate
If-Modified-Since: Tue, 13 Feb 2007 19:37:50 GMT
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET
CLR 1.1.4322; .NET CLR 2.0.50727; Google-TR-1)
Host: groups.google.com
Connection: Keep-Alive
Cookie: GTZ=-60; __utma=118165087.413883557.1169431526.11731
but I've no idea how to extract source IP and GET's host and file with
awk
2012年9月26日 星期三
tracert v.s. traceroute using different protocal
最近再看facebook為什麼變慢,才發現 windows 的 tracert 跟 linux 的 traceroute 是用不同的東西在測試,分別是 ICMP 跟 UDP
參考資料: http://www.lslnet.com/linux/f/docs1/i33/big5257441.htm
參考資料: http://www.lslnet.com/linux/f/docs1/i33/big5257441.htm
2012年7月19日 星期四
JabRef 簡易使用方法 local & mysql (Windows)
Google Doc 網址: http://goo.gl/zykUu
好讀版: http://goo.gl/DtDNp
找到 jabref*-setup.exe下載

好讀版: http://goo.gl/DtDNp
- 下載 JabRef 安裝檔
找到 jabref*-setup.exe下載
- 安裝完成之後應該會在桌面出現JabRef的捷徑,點兩下開啟
- 開啟後畫面會像是這樣
- 點擊File -> New Database
- 這時候就建立了一個database(可視為一個bibtex檔),接下來就可以開始新增資料,有兩種新增方法,手動輸入的話,點擊綠色的+號會出現一個選單,選單的內容是你要自行輸入時,該條目的類型,通常的話應該是Article
- 畫面下半部就會出現可以輸入的欄位,接下來就按照欄位輸入就可以了,不過現在通常是由網路上找資料,我們可以直接引入,不用辛苦的自己打
- 在各大網站要怎麼找資料匯入近資料庫呢?在這邊舉三個網站(science direct, ieee explorer, springer link)為例子,其他網站應該也可以如法炮製,找到你要的文章之後,點擊文章連結進去可以發現有個連結名字為 EXPORT CITATION 或是 Download Citation的

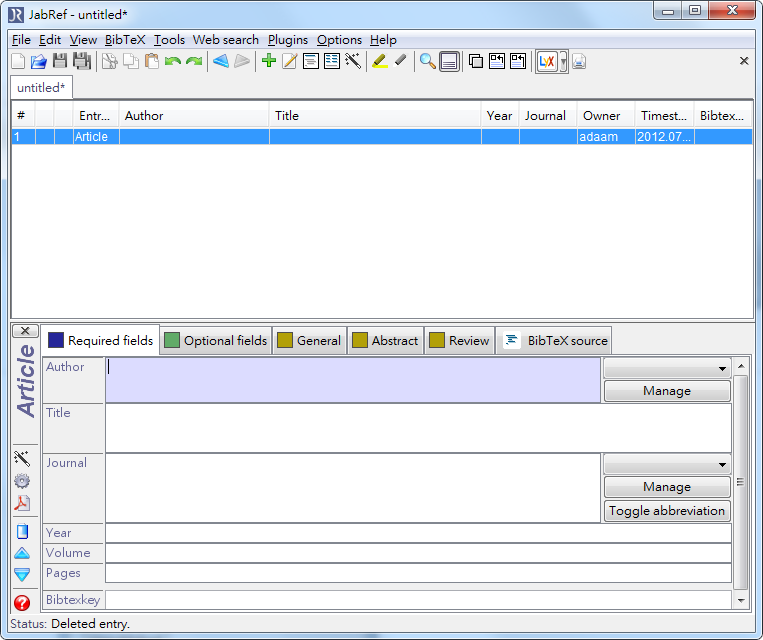
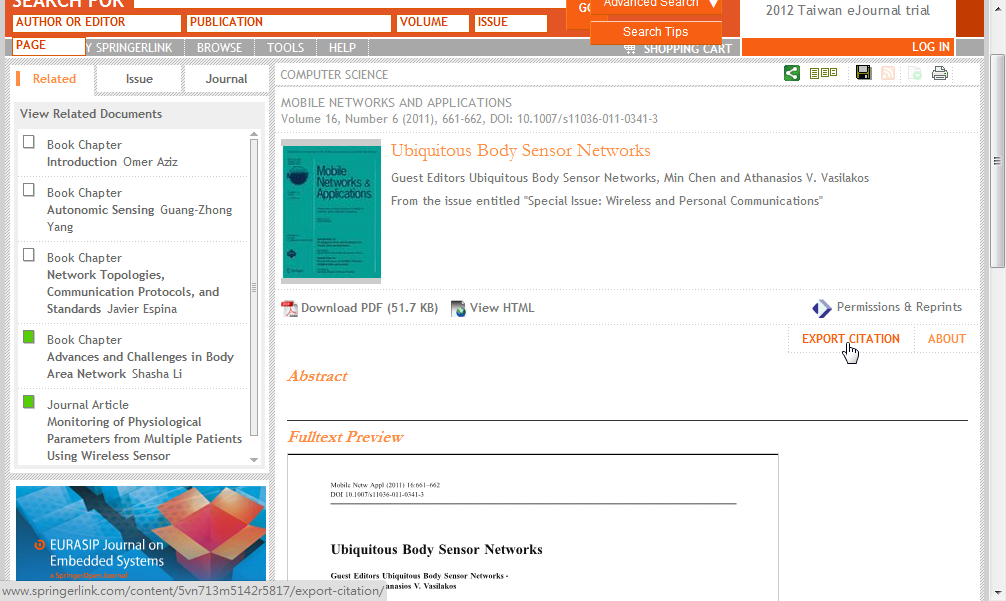

- 點進去之後可以選擇只要文章的索引或是要包含摘要,以及可以選擇要匯出索引的格式,在這邊我們都選包含摘要以及選擇的格式為BibTEX
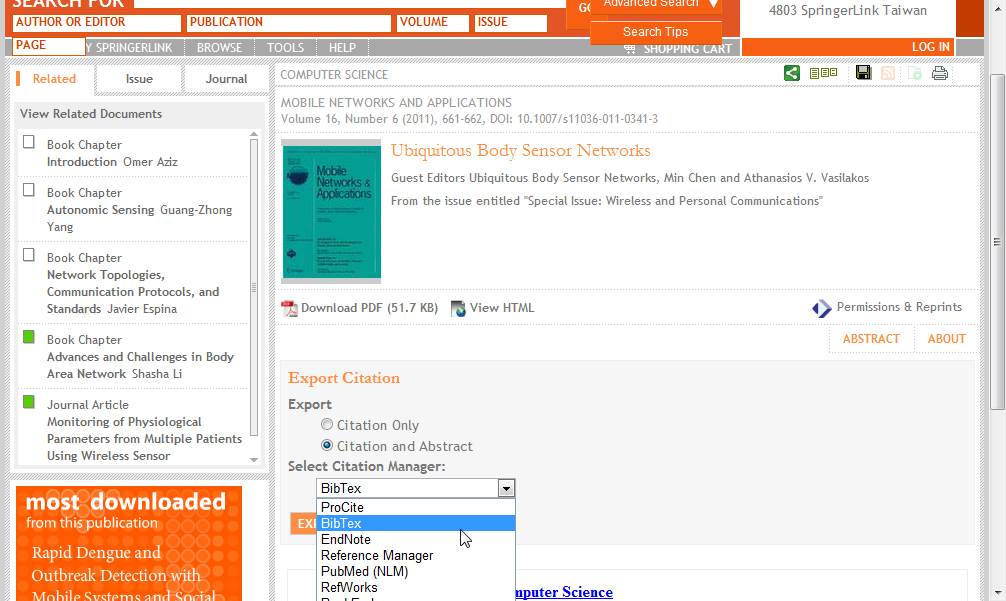


- 點擊之後有幾種狀況,像是science direct跟springer link都會下載下來檔案,而ieee explorer則是會直接顯示出bibtex格式的文字檔,理論上檔案應該都要可以直接匯入,可是springer的格式不知道為什麼在Windows上一直沒辦法成功,science direct的卻可以,下面以我們先講怎麼由檔案匯入
- 要匯入的話,點擊 File -> Inport to current database ,或是用久了應該也可以直接用快速鍵 Ctrl + I ,選取剛剛下載下來的檔案就可以匯入了,在出現的視窗點選OK
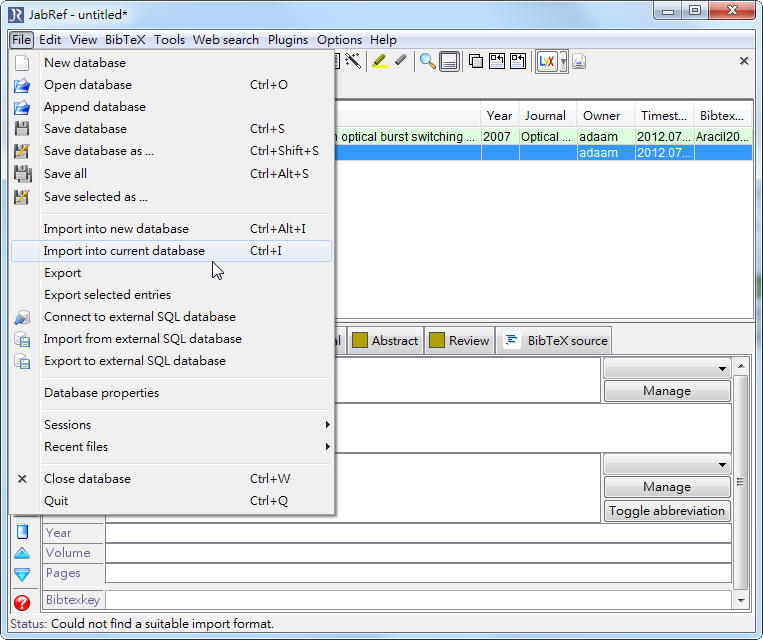


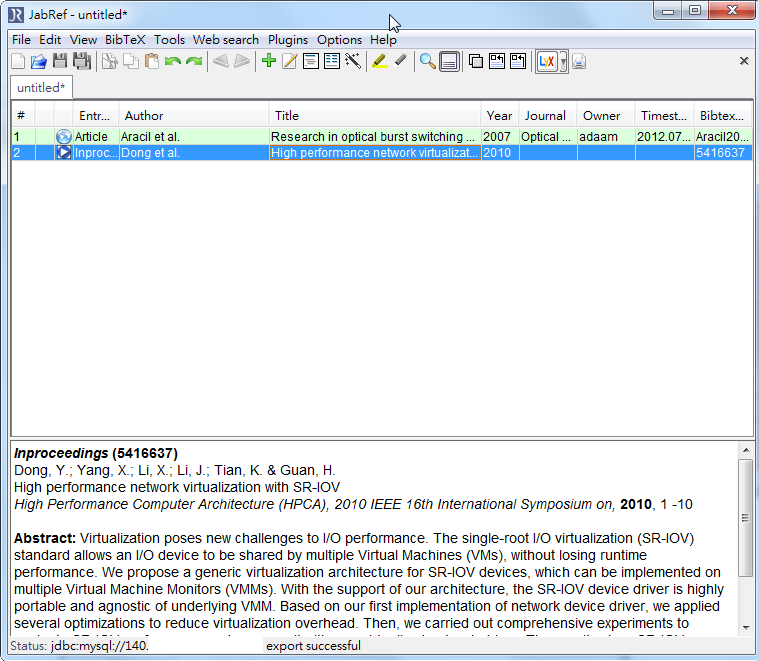
- 匯入成功會像是這樣子
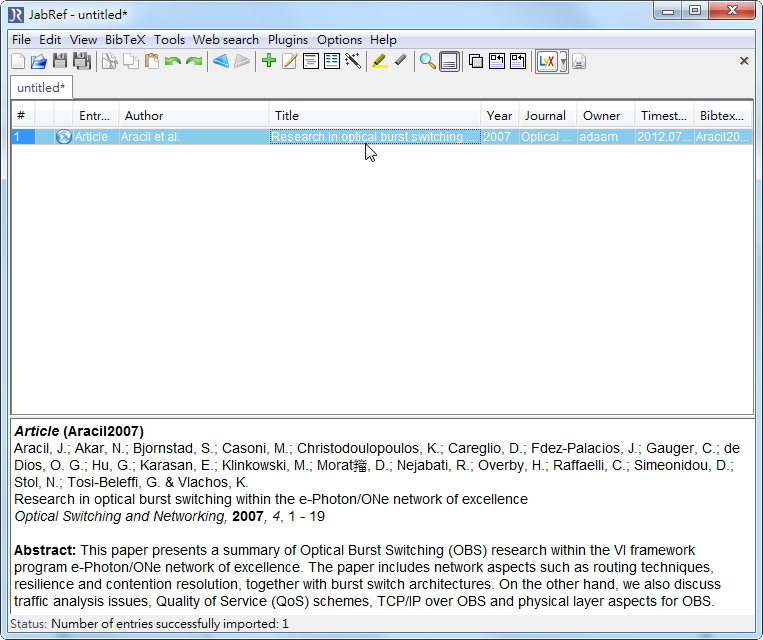
- springer link 跟 ieee explorer的匯入就稍微多幾個步驟,不知道為什麼springer link下載下來的格式在Winodws沒辦法匯入,可是在Linux板的JabRef卻可以,所以只好自己動手塞了,ieee explorer由於根本就沒有出現檔案,所以也要手動加入
- 首先跟手動輸入一樣,先點擊綠色的加號,在出現選單的時候選哪個都無所謂,因為我們等一下要直接編輯bibtex source
- 在這邊我們還是假設點的是 Artical,不過對後續沒影響,點擊之後會出現輸入視窗
- 點選下面視窗的BibTeX source 頁面
- ieee explorer的話就直接複製網頁上的文字貼上,springer link的話就用文字編輯器打開他的檔案,把內容複製貼上到欄位內,像這樣
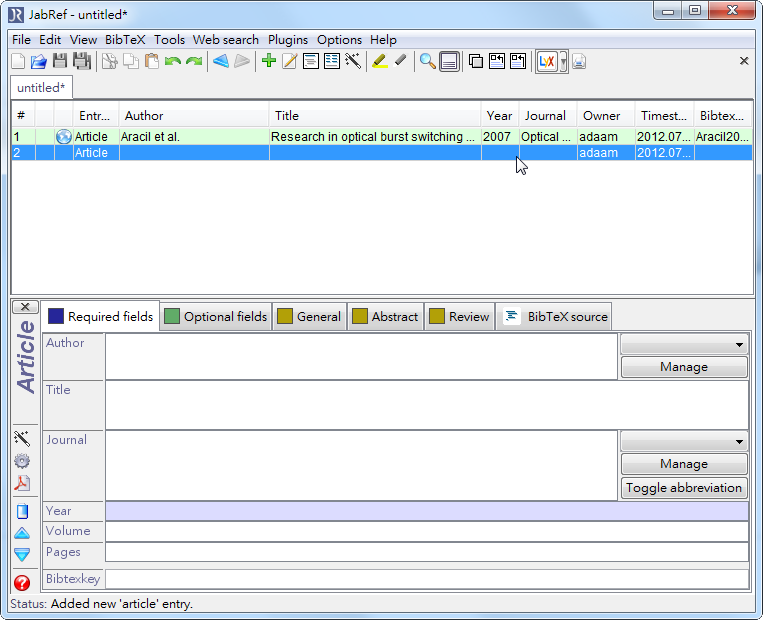
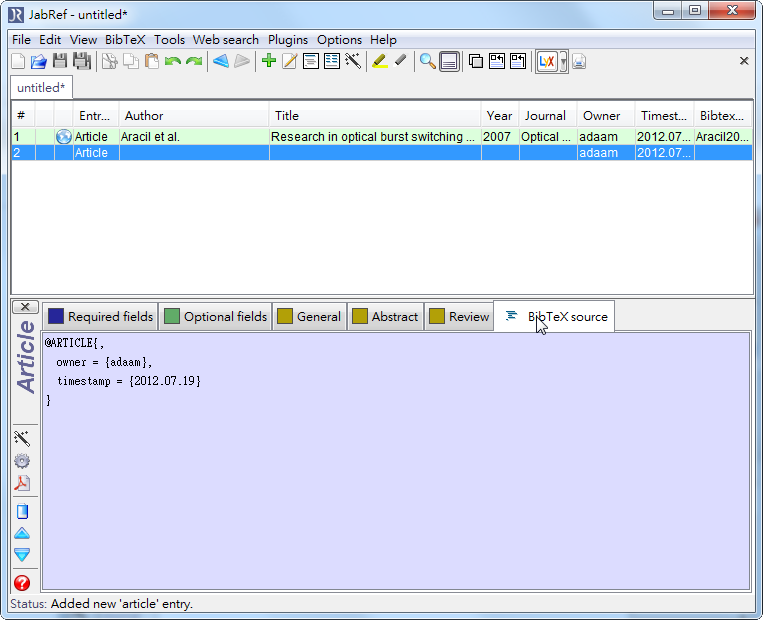
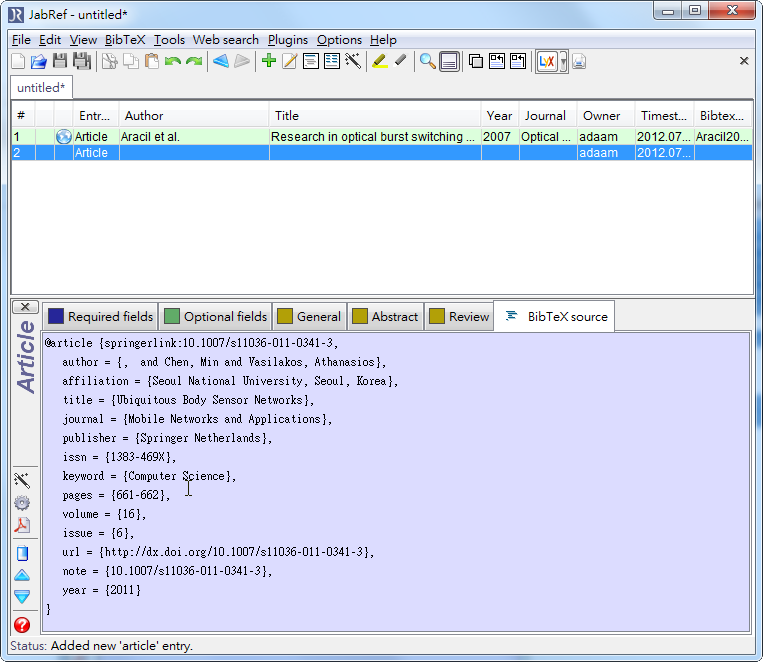
- 再來點擊其他頁面,資料就會更新,如Required fields
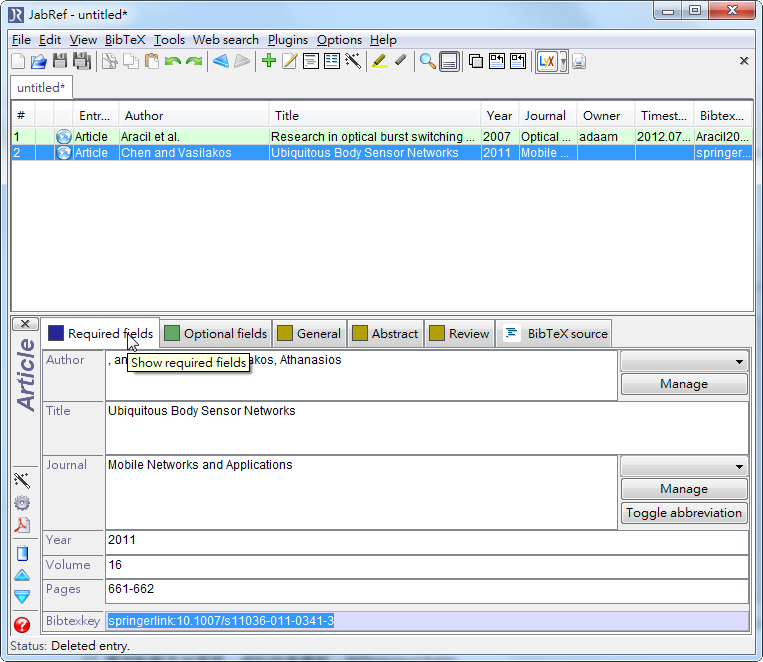
- 到目前為止我們就學會了怎麼輸入資料進JabRef,接下來我們就可以儲存檔案或是儲存去遠端的mysql
- 檔案的話比較單純,直接點擊 File -> Save database 或是 Save database as,意思就跟正常的儲存檔案以及另存新檔是一樣的意思,存好就OK了
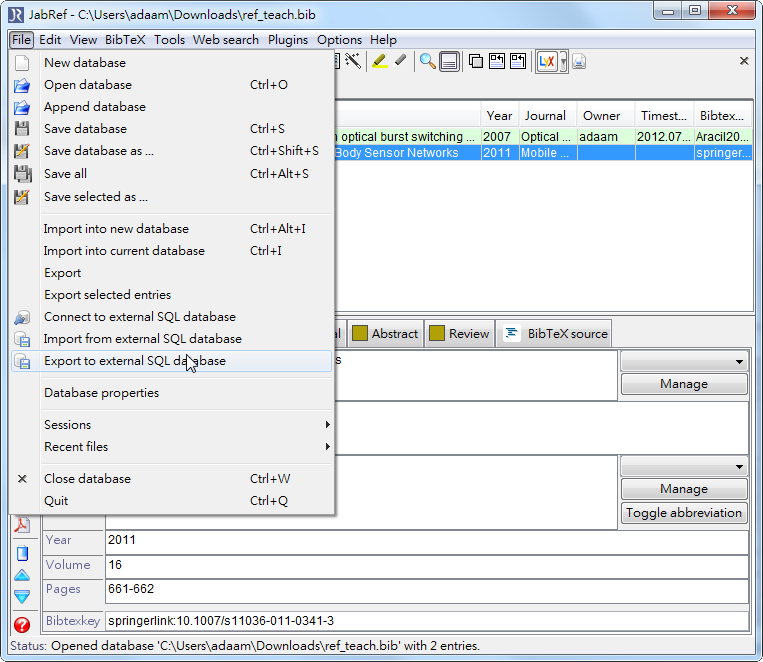
- 使用mysql的好處是可以在不同的地方看論文,以及輸入看過的論文資料,只要電腦可以執行JabRef就可以了,但是重點就在你的mysql要讓使用者可以從外面的 IP 連線,因為正常預設的話mysql server只允許自己本機端的連線,所以mysql的my.cnf以及自己的權限設定都要修改過才可以
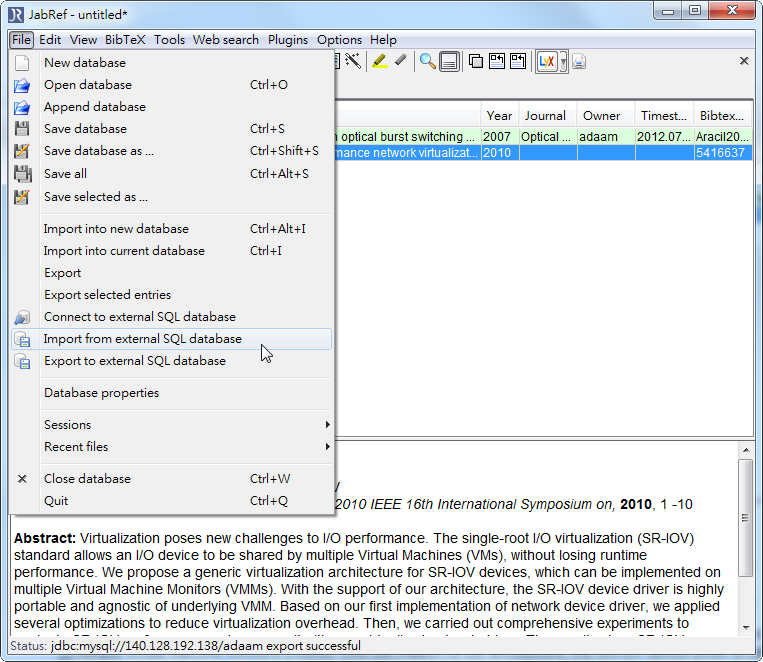
- 點擊 File -> export to external SQL database
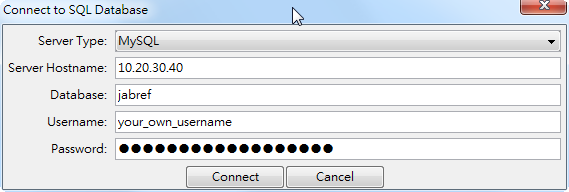
- 會出現視窗請你輸入要連結的主機、要儲存到哪個資料庫、資料庫的使用者名稱跟密碼,比較麻煩一點的是每次一關掉JabRef之後這些資訊不會儲存,所以要記好
- 成功的話會看到視窗最下面的狀態列會顯示 successful
- 匯出資料庫到這邊也就完成了
- 接下來就是怎麼把檔案讀回來的部分,也就是把建好的資料庫要重新編輯新增的話要怎麼做,檔案最簡單,如果你存成檔案的話,上次關JabRef也沒特別關掉,那下次開啟JabRef應該就會直接把檔案打開,就可以直接做新增了。
- mysql 要讀回來其實也不難,只是要把之前你匯出到哪台機器的資訊記好,也就是剛剛講過的server domain or IP, 資料庫名稱,使用者以及密碼,點擊 File -> Import from extrenal database
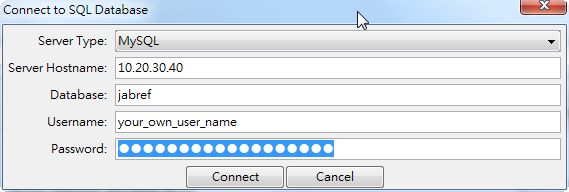
- 再來點選connect應該就會連接之後把資料讀回來囉
- 以上就是怎麼利用Jabref輸入文章資料,以及如何儲存在檔案或是mysql的介紹,下面稍微講一下怎麼使用你入的資料,應用在LaTeX上面來插入引用文獻,其實這才是最主要的目的,除了累積你自己看過哪些論文之外,在寫論文的時候可以快速引用才是大重點阿!!!
- 這邊先請大家稍微看一下網站的資料,因為我也還沒正式寫過,所以不知道下面的流程對不對
- 首先,本地端的檔案最沒有問題,就直接將你的檔案(假如檔名是mylib.bib)複製到你的tex檔案所在目錄,如果是mysql方式的話要先從遠端機器匯入,再存成檔案,照以下步驟做就可以引用
- 在你的TeX文件中\end之前 加入
\bibliographystyle{plain} #這個是指定引用文獻的顯示格式
\bibliography{refs} #這個是說讀取哪個bibtex file
- 之後再你的tex文件要引用文獻的地方的地方加入\cite{xxxx},xxxx的部份就是你在JabRef裡面可以看到的bibtexkey
- 輸入完之後,照文章的說法是先使用latex編譯一次,再來用bibtex編譯一次,之後再用latex編譯兩次,文章就完成了,至於是不是真的這樣子,就要等我之後有用到再說囉
- 大功告成!!
訂閱:
意見 (Atom)