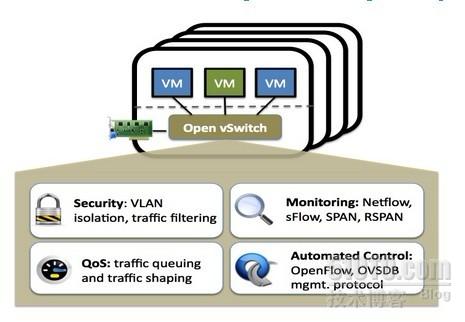
- ZFS的測試結果分析整理:(3) 我所了解的ZFS特性
關於ZFS的中文資料,對於ZFS的特性,大多只是重複官方的說明,對於比較詳細的部份,著墨不多,有些甚至變成以訛傳訛的狀況。
之前做過的一些ZFS測試,有發現到一些比較特別的特性,讓我變成ZFS的教徒,所以很想詳細介紹一下,拖了很久終於生出這篇說明。
因為是個人實驗結果的整理,加上沒有親自實驗的部份來自網路上的其他文章,有錯誤的部份請提出來更正,不必客氣。
原本想再把文字內容整理的更容易了解再發表,但是因為再拖下去大概永遠不會發表了,決定先上再說。
- checksum
這是ZFS的最大特色之一,所有資料包含metadata建立時都會產生對應的checksum,可以透過checksum比較,去發現silent data corruption,並且從正確的parity資料,去修復錯誤。
但是一般宣傳時,有一個最大的誤解是(ZFS永遠不會有silent data error),正確的是ZFS一樣會發生(因為silent data error的發生是來自硬碟本身,和上層的檔案系統沒有關係),但是只要定期進行scrub檢查或任何讀出資料的動作,ZFS就能透過checksum能夠判斷資料是否是有問題。
雖然只能判斷是否有問題發生後再進行修正,但是和傳統的RAID,只能發現資料錯誤,但是無法判斷是那一個parity出錯,也無法判斷那一組parity組合是正確的相比,可以說更加可靠。
題外話,我不熟硬體RAID,但是很好奇一點,在block底層額外占一點空間加上checksum檢查好像有可能,不知道是不是已經有那一家的硬體RAID,有提供這功能。畢竟ZFS的checksum也是用cpu、記憶體和硬碟空間換來的,沒理由硬體RAID不能做到,還是說因為沒有和檔案系統結合,從block level做其實問題很大,其實是相當困難。 - COW
ZFS的COW(copy on write),對於任何要寫入的資料,無論是現有資料修改還是新增資料,一律先找空間寫入硬碟,再去修改檔案系統的配置,假如我的記憶沒有錯,ZFS連檔案配置在內的所有metadata,也同樣是依照COW的原則來寫入。所以不只是影響檔案系統下的寫入方式,讓寫入更加迅速,同時也讓RAID-Z避免了類似RAID5的write hole的發生,大幅提高對斷電等異常的安全性。
雖然有容易增加Fragment的疑慮,但是ZIL造成的Fragment似乎更為主要。 - Resilver
在pool(應該是vdev比較正確)狀態有變動時(不論是異常還是手動變更組態),ZFS會自動進行Resilver,雖然Resilver也沒有辦法用手動的方式強制執行。
最常出現的狀況就是在mirror和RAID-Z等組態中,出現故障讓硬碟暫時離線後復原或手動用replace指令更換硬碟,一定會自動啟動Resilver進行資料的同步,基本上就是一般陣列的rebuild重建,但是配合ZFS的檔案系統和陣列整合的特性,只會重建被更換的硬碟中有資料的部份,其他未使用的空間和不相同的vdev群組,ZFS並不會浪費時間去重建。甚至對於一些只是像排線接觸不良暫時離線的硬碟,在Resilver過程,也只會對離線中所修改的資料進行重建,而不必重建所有的資料。
Resilver中每次重開機的動作,都會讓Resilver的進度百分比從頭開始,那是因為ZFS是日誌型的檔案系統,Resilver只會針對日誌最後變動以來的部分進行,實際上根據ZFS日誌已經完成的部分,是不會對相同資料重複進行Resilver的。雖然出現異常自動進行Resilver時,為了資料的安全最好是讓Resilver先完成再說。 - scrub
一般情況下scrub是必須手動進行的,有點接近一般RAID陣列的rebuild重建,但是考慮到scrub檢查的是資料的checksum是否正確,只有在發現錯誤時才會有重新寫入正確資料的動作,應該是比較接近一般RAID陣列的完整性檢查。
和一般陣列相比,因為有checksum做為判斷的基準,能夠分辨出parity之中錯誤和正確的部份,並且從正確的parity中還原正確資料並加以修正。同樣的,因為和檔案系統結合,scrub只會針對有效的資料進行,不會對未使用的空間進行檢查,在效率上非常優秀。對於相同pool中的vdev也是同時進行,所以整體的完成速度,只要cpu夠力,通常只受到最慢和使用容量最大的硬碟限制。
除了定期進行scrub之外,通常在出現異常狀況,完成Resilver後,最好是再進行一次scrub好確保資料的完整性,因為以我之前的測試結果,ZFS在最極端的情況下,還是有可能發生Resilver檢查不到的錯誤(雖然那實驗已經算是惡意破壞了)。
假如在scrub進行中進行重開機,scrub進度百分比會接續在上次關機前的進度,同樣不用擔心關機會造成scrub不斷重來。 - snapshot
ZFS在進行snapshot時,我的猜測是有點接近在檔案記錄的樹狀圖上產生另外一個分支,所以建立snapshot的速度幾乎是瞬間,也不須要預留空間。
在和OpenSolaris內建的CIFS分享整合後,在windows底下snapshot會出現在以前的版本裡,和Windows使用系統保護產生的還原點相同,使用檔案總管就可以很方便的依snapshot建立時間找到舊版本的檔案,因為實在太方便,反而是ZFS自己的還原snapshot功能我不太會用。至於不用OpenSolaris內建的CIFS改用samba是否能提供相同的功能,我就不知道了。 - ZIL
為了要滿足要求同步的寫入要求,必須將資料寫入非輝發性的媒體中,再回報寫入完成。
所以ZFS準備了ZIL(ZFS intent log)負責在有同步寫入的要求出現時,就把資料先寫入ZIL後就先回報寫入完成,再找時間把的資料從記憶體內真正寫入zpool(這樣也能把一部份隨機寫入,變成效率比較高的連續寫入),最後再清除ZIL和記憶體的資料。
所以基本上zpool中一定有ZIL(ZFS intent log)的存在,ZIL一般是自動分配在zpool的vdev之中,但是在一般使用情況下ZIL只會有連續寫入(等於只是暫存,所以隨機資料一樣排隊當連續寫入),不會有從ZIL讀出資料的動作,只有在斷電或異常當機時,ZFS會透過日誌判斷那些ZIL的資料,沒有從記憶體內正確的寫入zpool,這時才會從ZIL讀取資料,完成寫入zpool的動作。
因為是分配在zpool的vdev之中,速度自然是受到zpool組態的限制,這種一般的組態下,ZIL和zpool重覆寫入,比較容易產生Fragment,對效能自然有比較大的影響,所以ZFS提供了一個先進的解決方案,可以使用獨立的ZIL,不必分配在zpool的vdev之中,不只減少Fragment,也能夠提高寫入性能。
所以網路上就出現了使用SSD當獨立ZIL後,提高整個zpool隨機寫入效能的範例,除了原本SSD小檔案隨機寫入舊優於機械式硬碟外,在ZIL會把小檔案直接連續寫入的狀況下,這種效果就會在ZFS將小檔案變成連續寫入的優點凸顯出來(不過小檔案多到,連記憶體都裝滿,zpool寫入跟不上的時候,應該還是會受到zpool本身的寫入限制吧)。
更進一步還有拿ramdisk當ZIL的測試,帳面數字很高(但是實際上和一般狀況的差異,已經超過我能理解的)範圍,不過ramdisk當ZIL這點是我倒是很想玩玩看的。
還有些測試顯示,直接關掉ZIL,ZFS的寫入效能最高,因為所有要求同步寫入的資料,都和非同步的資料一樣,暫時放在記憶體,同時也省略了ZIL的寫入動作。只是沒有ZIL,對資料的安全有很大的影響,所有的測試都強調,一般狀況下不要關掉ZIL。
部份較舊的zpool版本(v19之前),獨立ZIL故障會讓zpool無法正常import,因為在import時會檢查ZIL內的資料是否已經正確寫入zpool完成必要的資料寫入,但是故障的ZIL會讓這個動作無法完成,所以一般都是建議,資料重要的情況下,ZIL應該用mirror的組態,讓ZIL本身有備援。
只有新的zpool版本(v19以後),才能在獨立ZIL故障下,維持正常將zpool進行import,只損失獨立ZIL內未寫入的資料,但是zpool的資料還完好,使用獨立ZIL請注意這點。 - L2arc
ZFS的第一層在記憶體的快取叫arc,所以第二層就叫L2arc,L2arc是獨立的裝置,必須另外設定增加到zpool組態中,可以用比記憶體大很多的空間來快取資料。
和ZIL不同的是,因為是快取裝置,所以故障並不會造成任何資料損失,原本的資料還是完好的儲存在zpool裡面,一般多是用讀取寫入快速的SSD做L2arc。
L2arc本身需要做一段類似暖身的動作,假如觀察L2arc的讀寫動作,一般第一次寫入的資料,並不會進入L2arc,當資料第一次從zpool讀取時,這時候才會看到重覆讀取的資料,同時寫入L2arc,這之後再讀取相同資料,才會有從L2arc讀取資料的加速效果。
比較特別的是,假如讀取的資料不大,或是是ZFS系統的記憶體又夠大,ARC可以放的下讀取的資料,就只會觀察到寫入L2arc的動作,但是重覆讀取還是由記憶體中的ARC負責,因為記憶體的ARC空間還是足夠。 - zpool
zpool => vdev => HDD - vdev
zpool在組成和存取資料時的基本單位,vdev可以視為一個在zpool內虛擬的硬碟(裝置),所有的zpool都是由vdev所組成,vdev本身再由單一硬碟、mirror和RAID-Z等不同組態形成。
ZFS在將資料寫入zpool時,會自動將資料分配在zpool內的各vdev,接近RAID0但是並非100%等分,而是動態分配至各vdev,ZFS會依各vdev的狀態(online、degrade),決定寫入資料的分配方式。
讀取時因為動態分配寫入的特性,會同時從哪幾個vdev讀取,全看寫入資料時的分布狀態,所以理想狀態會接近RAID0的讀取,最差的狀況就是從單一vdev讀取的速度。
vdev的數量,影響iops的高低,所以zpool組成中總硬碟數量相同時,分成較多組小的vdev,通常會損失較多有效容量(vdev是有備援的RAID-Z和mirror情況下),但是可以提高iops。 - vdev組態RAID-Z
從RAID-Z1、RAID-Z2到RAID-Z3的備援組態,分別允許vdev組成之中有1到3個的硬碟損壞,還能保持資料的完整,而效能的部份,每一組RAID-Z組成的vdev讀寫頻寬大約是RAID-Z1(n-1)、RAID-Z2(n-2)、RAID-Z3(n-3),每一組vdev的iops約等於單一硬碟,所以保護和效能大約就是和一般的RAID5和RAID6相似。
但是因為ZFS的COW和動態分割大小等特性,並不會有write hole 的問題發生,因為在寫入資料時,不需要因為儲存資料的block共用問題,去讀取資料再把更新後的資料寫入,所以不會發生要寫入資料A,結果因為意外寫入資料未完成,所以連原本完整的資料B(和資料A共用block)都一起出問題。
同時也因為寫入前不必有讀取的動作,自然在效能上占有優勢。 - vdev組態mirror
mirror基本上就是RAID1,但ZFS的mirror可以用2個以上的硬碟,為了安全可以用上3個甚至4個硬碟mirror(數量上限要查)。
配合ZFS的checksum功能,讀取資料時可以從vdev中的硬碟,分別讀取不同區塊的資料,進行checksum檢查ok後再合併資料輸出,所以讀取效能接近RAID0。
寫入效能因為是mirror,所以vdev中的每一個硬碟都要寫入相同資料,所以寫入效能接近RAID1。
另外,在較新的zpool版本,mirror可以使用split指令分開為獨立的兩個zpool - zpool擴充方式
想要擴充zpool的容量,最基本的方式就是增加新的vdev到zpool之中,新的vdev可以是單顆硬碟、mirror及RAID-Z任一種組態。加入新的vdev之後增加的空間,立刻就會反應到檔案系統上,存在舊有vdev上的資料,則會保持在原本的位置。
不過,已經加入zpool的vdev沒有辦法單獨移除,需要破壞zpool再進行重建,才能改變zpool的組態。(在zpool v28以上,ZIL和cache這兩種vdev,可以直接在線上進行加入和移除,算是例外。) - vdev的擴充
再進一步討論到vdev的擴充,最基本的原則就是vdev本身的組成(單一硬碟、mirror或RAID-Z),在建立之後就沒辦法變更。想要擴充vdev的容量,就只能用replace指令一次一個將組成的硬碟換成容量較大的,並且等待Resilver完成再換下一個硬碟,直到vdev中所有硬碟都替換並Resilver完成,最後再將zpool export後再重新import,這樣就可以完成vdev的擴充,增加的容量就可以被ZFS使用。 - zpool在異常狀況下的讀取行為,要由下往上由HDD、vdev到zpool的層級來看
對於最底層的HDD,除了完全無法讀取的狀況外,ZFS基本上是能讀取多少就讀取多少,再由checksum決定資料是否可以使用,所以和一般硬體RAID會利用類似TLEA指令讓問題HDD提早離線,盡早讓Hot Spare的HDD替換上來的原則不同,所以ZFS希望直接控制底層的HDD,而不要在硬體RAID之上使用ZFS,太早就把問題HDD離線,正是理由之一,畢竟兩種處理原則是有衝突的。ZFS針對checksum異常太多的HDD,才會把HDD設為offline(我不是很確定條件),無法再進行存取。
從vdev的層級來看,單一HDD組成的vdev因為沒有任何備援,所以異常狀態下vdev的讀取行為大致上和單一HDD相同。(這部分到是沒有測試過,也想不到要用沒有備援的vdev和zpool的理由)
異常狀況下,mirror和RAID-Z組成的vdev很相似,假如組成vdev的HDD只是有讀取異常(chechsum錯誤或部分無法讀取的資料),基本上就從其他正常的HDD取得checksum正確的資料。同時會利用其他HDD正確的資料,重新寫入讀取錯誤的HDD,回復資料的備援狀態。
假如是有HDD因為異常過多,被ZFS判定為fail而offline(或是被拔線),mirror的讀取效能就會受到影響,因為原本分散讀取的來源變少了,RAID-Z部分因為原本就要從vdev中所有的HDD讀取資料,我之前的測試顯示連續讀取的效能並沒有明顯的影響,可能因為ZFS並不會浪費時間在offline和fail的HDD上。
從zpool的層級來看,因為zpool中的vdev大約等於RAID0中的HDD,只是資料並不是完全平均分布在所有的vdev之中,所以一但vdev因為底下的HDD異常讓vdev進入fail或offline狀態,就看動態分配的資料有沒有在fail的vdev之中,來決定資料能不能讀出來,所以有機會只有有部分資料被影響。但是大部分的情況下,因為通常資料都還是接近平均分配,所以vdev故障和RAID0相同,代表著zpool的資料無法讀取。 - zpool在異常狀況下的寫入行為,要反過來由上往上下zpool、vdev到HDD的層級來看
對於最上層的zpool,由底下組成的vdev狀態決定,只要有任何vdev是fail,整個zpool就是fail狀態,系統是完全無法寫入資料,當然開機時也就無法mount。
假如有其中之一的vdev進入degrade狀態,整個zpool就會進入degrade狀態,在只有單一vdev組成的zpool中,會繼續寫入僅有的vdev之中,因為ZFS也沒有其他的選擇,但是因為ZFS動態分配寫入資料的特性,對於多個vdev所組成的zpool,只要正常的vdev空間足夠,ZFS在動態分配寫入資料時,就會避開已經是degrade狀態的vdev,只把資料寫入有正常備援保護的vdev中,確保資料備援的完整性。
在我之前測試結顯示,就算所有的vdev目前的狀態是正常的,也似乎會因為vdev曾經進入fail或是degrade狀態,而讓動態分配寫入的優先順序改變,只是之前的測試時在是判斷不出判斷優先順序的規則。
最後針對最底層的HDD,基本上最單純,就是盡可能的寫入資料,直到錯誤太多被判定成fail(mirror和RAID-Z等有備援上層vdev進入degrade狀態,沒有備援的vdev就直接進入fail)或degrade(上層vdev進入degrade)。 同樣的,對於架構在硬體RAID之上的ZFS系統,因為無從控制硬體RAID對異常的處理方式,上列的安全機制是完全沒有作用的,這是同樣是另一個盡量讓ZFS直接存取底層HDD的理由。 - 正常和異常狀態下,使用replace指令更換HDD
除了和一般RAID相同,拔舊的換新的HDD這種1對1交換外,只要還有足夠的port和電源,新舊HDD可以同時接上,也可以同時有兩組以上HDD進行交換。從我之前的實驗中,可以發現下列幾個優點。
對於正常的zpool,在舊HDD存在的情況下,不會進入degrade狀態,可以保持完整的備援,同時進行新HDD的Resilver動作。更進一步,因為可以同時從舊HDD讀取資料,只要還沒達到新HDD的寫入限制前,還有機會提高Resilver的速度。
對於degrade的zpool,只要舊HDD沒有進入完全無法讀取的fail狀態,除了舊HDD終無法讀取的資料失去備援外,其他還能讀取的資料還是能保持完整的備援,不會因為1對1交換而進入沒有備援狀態。同樣的Resilver時,也會盡可能讀取還能正常讀取的部分,來加速Resilver的完成。
所以使用ZFS需要更換HDD時,只要還有足夠的port和電源,請盡可能同時接上新舊HDD,不只提高安全性,還有機會縮短完成交換的時間。